

美团云“零感知”在线迁移解决方案
内核报错、CPU工作不正常、硬盘故障、业务扩展导致性能出现瓶颈……..这些都是运维工程师们的噩梦。怎样积极、有效地预防故障的发生?如何主动提高运维可靠性?在性能危机出现时,怎样化解?所有这些问题,在美团云的“零感知”在线迁移解决方案中,都能找到答案。
在线迁移是什么?
Live Migration (在线迁移)是指将一台虚拟机从其所在物理机无缝地转移到另一台物理机的过程。
哪些场景下会用到在线迁移?
场景一:
*在物理机发生内核报错、CPU工作不正常等底层基础设施故障时,管理员可以将虚拟机迁移到状态正常的物理机上,提前预防更恶劣的故障发生,比如机器彻底宕机。
场景二:
*物理机硬盘故障,尽管云服务商往往使用了多副本的存储方式保障可靠性,即某块盘坏了另一块能够继续服务。但是坏盘送修往往有一定的时间窗口,在这段时间内将关键业务在线迁移走也是一种更为安全的选择。
场景三:
*云计算服务商存在批量采购新机器,以及淘汰旧有机器的现象,可能某次采购之后,机器资源池有富余,这时候可以将老用户的机器均匀迁移到新机器上,以便提升性能。
场景四:
*用户的某些机器上承载的业务发生变化,负载持续过高,性能下降,可以联系云计算服务商进行主动迁移。
场景五:
*共享块存储服务(EBS)大大降低了在线迁移的成本,对用户来说,在上层业务暂时没有做到高可用性的情况下,可以通过将数据存在云端,底层快速保障就绪这种方式来提高可用性。
为什么美团云的在线迁移方式被称为“零感知”?
传统情况下,在数据迁移的过程中,用户的业务会被迫中断,因此被称为“冷迁移”。相反,美团云采用了“热迁移”方式,整个过程中,不关机不断网,用户业务始终不会中断。同时,无需运维介入,美团云能够替用户选择迁移路径及时间点,并进行高效的集中式运维管理。因此无论从业务角度,还是运维角度,美团云的迁移方案对用户来说,都是“零感知”的。
美团云如何做到“零感知” ?
美团云主机所采用的 QEMU/KVM 架构,对在线迁移技术有着较为成熟的支持。在软件实现上,为了追求对底层更加准确的控制,并没有使用例如 libvirt 这样的库,而是直接通过代码操作 QEMU 以及 QEMU monitor。在硬件上,物理机全部接入万兆网卡,同步内存的速度能够达到几百MB每秒,提升迁移成功率。
迁移过程是怎样的?
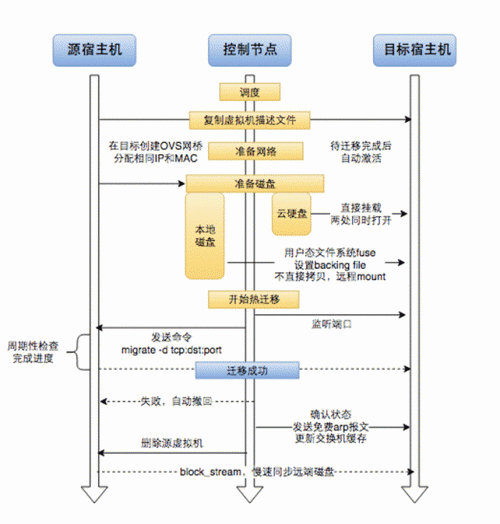
迁移虚拟机其实就是分别迁移网络、磁盘、机器状态(内存)的过程,假设源宿主机为A,迁移目标宿主机为B,我们会首先在B上启动一个空壳的虚拟机(QEMU进程),然后按照网络、磁盘、内存的顺序把A上面的QEMU转移过来。通过查看整个迁移过程的细节,我们能够明白为什么整个迁移过程完全是“无感知”的。
-第一步:网络
由于使用了Open vSwitch,我们可以很方便地在目标物理机上配置出完全相同的网桥,并且给将要到来的虚拟机分配相同的IP及MAC地址,这时候网络就算是就绪了,直到机器状态发生转移的那一瞬间,网络流量也会自然而然地由A切到B上,一个完全相同的虚拟网卡开始在B上工作了。但是这里还存在一个小问题,网络上的交换机内部有arp缓存,它仍然认为虚拟机MAC地址对应的这块网卡是在A而不是在B上,所以我们的控制程序需要在完成迁移后立刻从B向网络上发送一个免费arp报文,让交换机能够学习到新的地址。在这段时间内网络是不可用的,但由于时间非常短(几十毫秒左右),在TCP的超时重传范围内,因此基本不会被业务感知。
-第二步:磁盘
对于磁盘来说,通常对于这种块设备的迁移有两种方法。
一种是基于共享存储(EBS)的,支持在多点同时打开同一块盘。于是在B的虚拟机空壳上我们也会挂载上原先的这块磁盘,并且由QEMU自身保证。如果存在写入,则先在A上写,直到迁移完成的瞬间才开始在B上写。单点写入能够保证数据的一致性。
另一种方案是针对本地存储的。美团云的默认磁盘使用的是本地存储,为了避免迁移的时候需要拷贝大磁盘,我们使用了一个用户态的文件系统工具 fuse,它既可以像NFS一样方便地使用mount远程挂载磁盘,同时以用户态程序规避了内核难以调试的问题,并且和http整合到一起,形成了一个服务。在B端的空壳QEMU上新准备的磁盘也是空的,使用fuse mount 挂载A上的远程磁盘文件,并将其设置成空壳QEMU的 backing_file,凭借QEMU的copy_on_write 技术,A上的磁盘对于B的虚拟机来说变成本地可用。当内存迁移完成,新QEMU在B上运行后,我们还需要往B的QEMU monitor上发送block_stream 命令,以一个较小的速度(30MB/s)从A上同步磁盘,这个同步动作和用户在虚拟机内部的IO访问是不冲突的,用户这段时间做出的磁盘修改都会被记录在B本地,直到最终同步完成,才会去 merge 这些差异的数据。
因此这两种方案都能保证迁移的过程中磁盘的数据同步过程中,原来的数据盘A都是可用的,从而保证原有的业务不会中断。
-第三部:内存
最后一步是迁移内存。假设某个时刻网络和磁盘都在B上就绪了,虚拟机的整个系统仍然在A上运行着,为了保证业务不中断,我们一边从A往B拷贝着内存,填充空壳,另一方面仍然不能暂停A上QEMU的运行。但是只要在运行,内存就会有变化,可能拷贝了几十秒后(由网速决定)达到终点,但此时原先拷贝过的区域内一部分内存又变化了,因此,QEMU自身会在拷贝过程中记录下那些发生变化的脏页,针对它们再进行一次拷贝,如此循环。由于拷贝速度比内存变化速度快,所以在某个时刻,A与B上的QEMU内存会达到完全一致,A主动终止执行下一条CPU指令,B随即按照程序栈接替A执行,这样便完成了虚拟机系统从A到B的无缝切换。
下面就是整个迁移过程的框架:
美团云”零感知“迁移技术最大的技术难点是什么?
在同步内存这块,迁移速度的选择是一个技术难点。速度太大,过度占用网卡带宽,宿主机负载很重,容易影响其他用户体验;速度太小,脏页一直增长,来不及同步,导致一直迁移中无法结束。
脏页的问题,曾经遇到过这样一个场景。某个网站用户要求做迁移,迁移的时间段内。网站的访问量也很大,内存同步速度赶不上网站内存的变化速度。因此,美团云将迁移速度作为重要的备选参数,使得管理员能够针对不同的用户需求动态调整。从而在各种情况下,提高迁移成功率,做到真正的“零感知”解决方案。
我们还在做什么?
在最新的QEMU 2.5版本中,我们注意到,一个被称作为自动收敛(autoconverge)的功能被集成到了迁移代码里,它通过适当降低虚拟CPU执行速度的方法,间接降低了内存变化速度,从而提升迁移成功率。
此外,还有一个新特性叫 post-copy,它跟原先这种同步内存的方式(pre-copy)比起来,能够在第一时间就去B端将QEMU空壳启动起来,然后通过page fault 的方式按需去A端读内存,这样一来,虽然同步的过程比较长,但能够避免集中拷贝大段内存,从而提高迁移成功率。
美团云正在不断迭代,试图在更严峻的环境下,为用户提供真正“零感知”的在线迁移解决方案,从而大幅度提高云服务的可靠性,并降低运维的依赖性。这样靠谱的云,你值得拥有!
